Since our messaging services copy a message directly from the address space of one thread to another without intermediate buffering, the message-delivery performance approaches the memory bandwidth of the underlying hardware.
The kernel attaches no special meaning to the content of a message—the data in a message has meaning only as mutually defined by sender and receiver. However, “well-defined” message types are also provided so that user-written processes or threads can augment or substitute for system-supplied services.
The messaging primitives support multipart transfers, so that a message delivered from the address space of one thread to another needn't pre-exist in a single, contiguous buffer. Instead, both the sending and receiving threads can specify a vector table that indicates where the sending and receiving message fragments reside in memory. Note that the size of the various parts can be different for the sender and receiver.
Multipart transfers allow messages that have a header block separate from the data block to be sent without performance-consuming copying of the data to create a contiguous message. In addition, if the underlying data structure is a ring buffer, specifying a three-part message will allow a header and two disjoint ranges within the ring buffer to be sent as a single atomic message. A hardware equivalent of this concept would be that of a scatter/gather DMA facility.
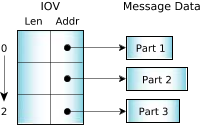 Figure 1. A multipart transfer.
Figure 1. A multipart transfer.Each IOV can have a maximum of 524288 parts. The sum of the sizes of the parts must not exceed INT_MAX.
The multipart transfers are also used extensively by filesystems. On a read, the data is copied directly from the filesystem cache into the application using a message with n parts for the data. Each part points into the cache and compensates for the fact that cache blocks aren't contiguous in memory with a read starting or ending within a block.
For example, with a cache block size of 512 bytes, a read of 1454 bytes can be satisfied with a five-part message:
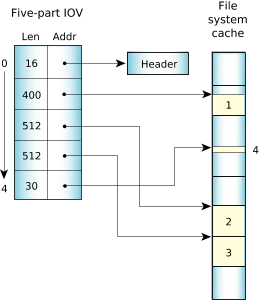 Figure 2. Scatter/gather of a read of 1454 bytes.
Figure 2. Scatter/gather of a read of 1454 bytes.Since message data is explicitly copied between address spaces (rather than by doing page table manipulations), messages can be easily allocated on the stack instead of from a special pool of page-aligned memory for MMU “page flipping.” As a result, many of the library routines that implement the API between client and server processes can be trivially expressed, without elaborate IPC-specific memory allocation calls.
For example, the code used by a client thread to request that the filesystem manager execute lseek on its behalf is implemented as follows:
#include <unistd.h>
#include <errno.h>
#include <sys/iomsg.h>
off64_t lseek64(int fd, off64_t offset, int whence) {
io_lseek_t msg;
off64_t off;
msg.i.type = _IO_LSEEK;
msg.i.combine_len = sizeof msg.i;
msg.i.offset = offset;
msg.i.whence = whence;
msg.i.zero = 0;
if(MsgSend(fd, &msg.i, sizeof msg.i, &off, sizeof off) == -1) {
return -1;
}
return off;
}
off_t lseek(int fd, off_t offset, int whence) {
return lseek64(fd, offset, whence);
}
This code essentially builds a message structure on the stack, populates it with various constants and passed parameters from the calling thread, and sends it to the filesystem manager associated with fd. The reply indicates the success or failure of the operation.