Let's first look at the “thread pool parameters” to see how you control the number and attributes of threads that will be operating in this thread pool. Keep in mind that we'll be talking about the “blocking operation” and the “processing operation” (when we look at the callout functions, we'll see how these relate to each other).
The following diagram illustrates the relationship of the lo_water, hi_water, and maximum parameters:
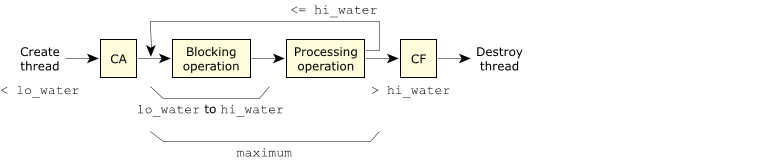 Figure 1. Thread flow when using thread pools.
Figure 1. Thread flow when using thread pools.(Note that “CA” is the context_alloc() function, “CF” is the context_free() function, “blocking operation” is the block_func() function, and “processing operation” is the handler_func().)
- attr
- This is the attributes structure that's used during thread creation. We've already discussed this structure above (in “The thread attributes structure”). You'll recall that this is the structure that controls things about the newly created thread like priority, stack size, and so on.
- lo_water
- There should always be at least lo_water threads sitting in the blocking operation. In a typical server, this would be the number of threads waiting to receive a message, for example. If there are less than lo_water threads sitting in the blocking operation (because, for example, we just received a message and have started the processing operation on that message), then more threads are created, according to the increment parameter. This is represented in the diagram by the first step labeled “create thread.”
- increment
- Indicates how many threads should be created at once if the count of blocking operation threads ever drops under lo_water. In deciding how to choose a value for this, you'd most likely start with 1. This means that if the number of threads in the blocking operation drops under lo_water, exactly one more thread would be created by the thread pool. To fine-tune the number that you've selected for increment, you could observe the behavior of the process and determine whether this number needs to be anything other than one. If, for example, you notice that your process gets “bursts” of requests, then you might decide that once you've dropped below lo_water blocking operation threads, you're probably going to encounter this “burst” of requests, so you might decide to request the creation of more than one thread at a time.
- hi_water
- Indicates the upper limit on the number of threads that should be in the blocking operation. As threads complete their processing operations, they will normally return to the blocking operation. However, the thread pool library keeps count of how many threads are currently in the blocking operation, and if that number ever exceeds hi_water, the thread pool library will kill the thread that caused the overflow (i.e., the thread that had just finished and was about to go back to the blocking operation). This is shown in the diagram as the “split” out of the “processing operation” block, with one path going to the “blocking operation” and the other path going to “CF” to destroy the thread. The combination of lo_water and hi_water, therefore, allows you to specify a range indicating how many threads should be in the blocking operation.
- maximum
- Indicates the absolute maximum number of threads that will ever run concurrently as a result of the thread pool library. For example, if threads were being created as a result of an underflow of the lo_water mark, the maximum parameter would limit the total number of threads.
- tid_name
- Either NULL or a pointer to a null-terminated name for the threads in the pool. Assigning a name to the threads can help simplify system debugging.
One other key parameter to controlling the threads is the flags parameter passed to the thread_pool_create() function. It can have one of the following values:
- POOL_FLAG_EXIT_SELF
- The thread_pool_start() function will not return, nor will the calling thread be incorporated into the pool of threads.
- POOL_FLAG_USE_SELF
- The thread_pool_start() function will not return, but the calling thread will be incorporated into the pool of threads.
If neither POOL_FLAG_EXIT_SELF nor POOL_FLAG_USE_SELF is set, the thread_pool_start() function will return, with new threads being created as required.
The above descriptions may seem a little dry. Let's look at an example.
You can find the complete version of tp1.c in the Sample Programs appendix. Here, we'll just focus on the lo_water, hi_water, increment, and the maximum members of the thread pool control structure:
/*
* part of tp1.c
*/
#include <sys/dispatch.h>
int
main ()
{
thread_pool_attr_t tp_attr;
void *tpp;
...
tp_attr.lo_water = 3;
tp_attr.increment = 2;
tp_attr.hi_water = 7;
tp_attr.maximum = 10;
...
tpp = thread_pool_create (&tp_attr, POOL_FLAG_USE_SELF);
if (tpp == NULL) {
fprintf (stderr,
"%s: can't thread_pool_create, errno %s\n",
progname, strerror (errno));
exit (EXIT_FAILURE);
}
thread_pool_start (tpp);
...
After setting the members, we call thread_pool_create() to create a thread pool. This returns a pointer to a thread pool control structure (tpp), which we check against NULL (which would indicate an error). Finally we call thread_pool_start() with the tpp thread pool control structure.
I've specified POOL_FLAG_USE_SELF which means that the thread that called thread_pool_start() will be considered an available thread for the thread pool. So, at this point, there is only that one thread in the thread pool library. Since we have a lo_water value of 3, the library immediately creates increment number of threads (2 in this case). At this point, 3 threads are in the library, and all 3 of them are in the blocking operation. The lo_water condition is satisfied, because there are at least that number of threads in the blocking operation; the hi_water condition is satisfied, because there are less than that number of threads in the blocking operation; and finally, the maximum condition is satisfied as well, because we don't have more than that number of threads in the thread pool library.
Now, one of the threads in the blocking operation unblocks (e.g., in a server application, a message was received). This means that now one of the three threads is no longer in the blocking operation (instead, that thread is now in the processing operation). Since the count of blocking threads is less than the lo_water, it trips the lo_water trigger and causes the library to create increment (2) threads. So now there are 5 threads total (4 in the blocking operation, and 1 in the processing operation).
More threads unblock. Let's assume that none of the threads in the processing operation none completes any of their requests yet. Here's a table illustrating this, starting at the initial state (we've used “Proc Op” for the processing operation, and “Blk Op” for the blocking operation, as we did in the previous diagram, “Thread flow when using thread pools.”):
| Event | Proc Op | Blk Op | Total |
|---|---|---|---|
| Initial | 0 | 1 | 1 |
| lo_water trip | 0 | 3 | 3 |
| Unblock | 1 | 2 | 3 |
| lo_water trip | 1 | 4 | 5 |
| Unblock | 2 | 3 | 5 |
| Unblock | 3 | 2 | 5 |
| lo_water trip | 3 | 4 | 7 |
| Unblock | 4 | 3 | 7 |
| Unblock | 5 | 2 | 7 |
| lo_water trip | 5 | 4 | 9 |
| Unblock | 6 | 3 | 9 |
| Unblock | 7 | 2 | 9 |
| lo_water trip | 7 | 3 | 10 |
| Unblock | 8 | 2 | 10 |
| Unblock | 9 | 1 | 10 |
| Unblock | 10 | 0 | 10 |
As you can see, the library always checks the lo_water variable and creates increment threads at a time until it hits the limit of the maximum variable (as it did when the “Total” column reached 10—no more threads were being created, even though the count had underflowed the lo_water).
This means that at this point, there are no more threads waiting in the blocking operation. Let's assume that the threads are now finishing their requests (from the processing operation); watch what happens with the hi_water trigger:
| Event | Proc Op | Blk Op | Total |
|---|---|---|---|
| Completion | 9 | 1 | 10 |
| Completion | 8 | 2 | 10 |
| Completion | 7 | 3 | 10 |
| Completion | 6 | 4 | 10 |
| Completion | 5 | 5 | 10 |
| Completion | 4 | 6 | 10 |
| Completion | 3 | 7 | 10 |
| Completion | 2 | 8 | 10 |
| hi_water trip | 2 | 7 | 9 |
| Completion | 1 | 8 | 9 |
| hi_water trip | 1 | 7 | 8 |
| Completion | 0 | 8 | 8 |
| hi_water trip | 0 | 7 | 7 |
Notice how nothing really happened during the completion of processing for the threads until we tripped over the hi_water trigger. The implementation is that as soon as the thread finishes, it looks at the number of receive blocked threads and decides to kill itself if there are too many (i.e., more than hi_water) waiting at that point. The nice thing about the lo_water and hi_water limits in the structures is that you can effectively have an “operating range” where a sufficient number of threads are available, and you're not unnecessarily creating and destroying threads. In our case, after the operations performed by the above tables, we now have a system that can handle up to 4 requests simultaneously without creating more threads (7 - 4 = 3, which is the lo_water trip).