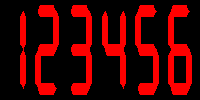
The web counter resource manager was created specifically for this book, and the code is presented in a three-phase building-block approach. In addition, there are a few interesting diversions that occurred along the way.
This chapter includes:
The requirements for the web counter resource manager are very simple — it dynamically generates a graphic file that contains a bitmap of the numbers representing the current hit count. The hit count is meant to indicate how many times the resource has been accessed. Further phases of the project refine this by adding font selection, directory management, and other features.
The web counter is very simple to use. As root, you run it in the background:
# webcounter &
The web counter is now running, and has taken over the pathname /dev/webcounter.gif. To see if it's really doing its job, you can run QNX's pv (Photon Viewer) module. I used my aview (Animation Viewer) program. If you test it using a web browser, you'll need to hit the reload or refresh button to get the next count to display.
To use it as part of a web page, you'd include it in an <img> tag:
<html> <head> <title>My Web Page</title> <body> <h1>My Web Page</h1> <p> My web page has been accessed this many times: <img src="/dev/webcounter.gif"> </p> </body> </html>
Of course, your web server must be set up to allow access to /dev/webcounter.gif — you can get around this by using a symlink, or by setting the name of the web counter output file on the command line (use -n):
# webcounter -n /home/rk/public_html/hits.gif &
The webcounter design was very ad-hoc — the requirements were that it display a graphical image to illustrate on-demand data generation in a resource manager. Most of the command-line options were defined right at the time that I edited main.c — things like the X and Y image size, the background and foreground colors, and so on. The -n parameter, to determine the name of the resource, was already part of the “standard” resource manager “framework” library that I use as a template. The -s option was added last. It controls the starting count, and after the first draft of the code was completed, I got bored with the fact that it always started at zero, and wanted to provide a way of getting an arbitrary count into the counter.
The hardest part of the design was generating the graphical image. I chose a 7-segment LED style because I figured it would be the easiest to generate. Of course, a plain 7-segment representation, where each segment was a rectangle, proved to be too simple, so I had to make the segments with a nice diagonal corner so they'd fit together nicely. Sometimes, I just have too much time on my hands.
The simulated 7-segment digits.
In this section, we'll discuss the code for the phase 1 implementation. In later sections, we'll examine the differences between this code and the phase 2 and phase 3 implementations.
The code consists of the following modules:
You'll also need a GIF encoder.
Operation begins in the usual manner with main() in main.c. We call our option processor (optproc()) and then we enter the resource manager main loop at execute_resmgr(). The resource manager main loop never returns.
All of the work is done as callouts by the connect and I/O functions of the resource manager. We take over the io_open(), io_read(), and io_close_ocb() functions, and leave all the rest to the QSSL-supplied libraries. This makes sense when you think about it — apart from the magic of generating a graphical image on-the-fly, all we're really doing is handling the client's open() (so we can set up our data areas), giving the data to the client (via the client's read()), and cleaning up after ourselves (when we get the client's close()).
However, as you'll see shortly, even these simple operations have some interesting consequences that need to be considered.
Part of the magic of this resource manager is generating the graphical image. The process is quite simple. We allocate an array to hold the graphical image as a bitmap. Then, we draw the 7-segment display into the bitmap, and finally we convert the bitmap into a GIF-encoded data block. It's the GIF-encoded data block — not the raw bitmap — that's returned by the io_read() handler to the client.
Let's look at the source for the web counter resource manager, starting with the include files.
This project uses the following include files:
The web counter resource manager uses the following source files:
Apart from those files, there's also a fairly generic Makefile for building the executable.
As usual, execution begins at main() in main.c. We won't talk about main(); it only does very basic command-line processing (via our optproc() function), and then calls execute_resmgr().
One thing that you'll notice right away is that we extended the attributes (iofunc_attr_t) and the OCB (iofunc_ocb_t) structures:
typedef struct my_attr_s
{
iofunc_attr_t base;
int count;
} my_attr_t;
typedef struct my_ocb_s
{
iofunc_ocb_t base;
unsigned char *output;
int size;
} my_ocb_t;
It's a resource manager convention to place the standard structure as the first member of the extended structure. Thus, both members named base are the nonextended versions.
 |
Extending the attributes and OCB structures is discussed in Getting Started with QNX Neutrino in the Resource Managers chapter. |
Recall that an instance of the attributes structure is created for each device. This means that for the device /dev/webcounter1.gif, there will be exactly one attributes structure. Our extension simply stores the current count value. We certainly could have placed that into a global variable, but that would be bad design. If it were a global variable, we would be prevented from manifesting multiple devices. Granted, the current example shows only one device, but it's good practice to make the architecture as flexible as possible, especially if it doesn't add undue complexity. Adding one field to an extended structure is certainly not a big issue.
Things get more interesting in the OCB extensions. The OCB structure is present on a per-open basis; if four clients have called open() and haven't closed their file descriptors yet, there will be four instances of the OCB structure.
This brings us to the first design issue. The initial design had an interesting bug. Originally, I reasoned that since the QSSL-supplied resource manager library allows only single-threaded access to the resource (our /dev/webcounter.gif), then it would be safe to place the GIF context (the output member) and the size of the resource (the size member) into global variables. This singled-threaded behavior is standard for resource managers, because the QSSL-supplied library locks the attributes structure before performing any I/O function callouts. Thus, I felt confident that there would be no problems.
In fact, during initial testing, there were no problems — only because I tested the resource manager with a single client at a time. I felt that this was an insufficient test, and ran it with multiple simultaneous clients:
# aview -df1 /dev/webcounter.gif & # aview -df1 /dev/webcounter.gif & # aview -df1 /dev/webcounter.gif & # aview -df1 /dev/webcounter.gif &
and that's when the first bug showed up. Obviously, the GIF context members needed to be stored on a per-client basis, because each client would be requesting a different version of the number (one client would be at 712, the next would be at 713, and so on). This was readily fixed by extending the OCB and adding the GIF context member output. (I really should have done this initially, but for some reason it didn't occur to me at the time.)
At this point, I thought all the problems were fixed; multiple clients would show the numbers happily incrementing, and each client would show a different number, just as you would expect.
Then, the second interesting bug hit. Occasionally, I'd see that some of the aview clients would show only part of the image; the bottom part of the image would be cut off. This glitch would clear itself up on the next refresh of the display, so I was initially at a loss to explain where the problem was. I even suspected aview, although it had worked flawlessly in the past.
The problem turned out to be subtle. Inside of the base attributes structure is a member called nbytes, which indicates the size of the resource. The “size of the resource” is the number of bytes that would be reported by ls -l — that is, the size of the “file” /dev/webcounter1.gif.
When you do an ls -l of the web counter, the size reported by ls is fetched from the attributes structure via ls's stat() call. You'd expect that the size of a resource wouldn't change, but it does! Since the GIF compression algorithm squeezes out redundancy in the source bitmap image, it will generate different sizes of output for each image that's presented to it. Because of the way that the io_read() callout works, it requires the nbytes member to be accurate. That's how io_read() determines that the client has reached the end of the resource.
The first client would open() the resource, and begin reading. This caused the GIF compression algorithm to generate a compressed output stream. Since I needed the size of the resource to match the number of bytes that are returned, I wrote the number of bytes output by the GIF compression algorithm into the attributes structure's nbytes member, thinking that was the correct place to put it.
But consider a second client, preempting the first client, and generating a new compressed GIF stream. The size of the second stream was placed into the attributes structure's nbytes member, resulting in a (potentially) different size for the resource! This means that when the first client resumed reading, it was now comparing the new nbytes member against a different value than the size of the stream it was processing! So, if the second client generated a shorter compressed data stream, the first client would be tricked into thinking that the data stream was shorter than it should be. The net result was the second bug: only part of the image would appear — the bottom would be cut off because the first client hit the end-of-file prematurely.
The solution, therefore, was to store the size of the resource on a per-client basis in the OCB, and force the size (the nbytes member of the attributes structure) to be the one appropriate to the current client. This is a bit of a kludge, in that we have a resource that has a varying size depending on who's looking at it. You certainly wouldn't run into this problem with a traditional file — all clients using the file get whatever happens to be in the file when they do their read(). If the file gets shorter during the time that they are doing their read(), it's only natural to return the shorter size to the client.
Effectively, what the web counter resource manager does is maintain virtual client-sensitive devices (mapped onto the same name), with each client getting a slightly different view of the contents.
Think about it this way. If we had a standalone program that generated GIF images, and we piped the output of that program to a file every time a client came along and opened the image, then multiple concurrent clients would get inconsistent views of the file contents. They'd have to resort to some kind of locking or serialization method. Instead, by storing the actual generated image, and its size, in the per-client data area (the OCB), we've eliminated this problem by taking a snapshot of the data that's relevant to the client, without the possibility of having another client upset this snapshot.
That's why we need the io_close_ocb() handler — to release the per-client context blocks that we generated in the io_open().
So what size do we give the resource when no clients are actively changing it? Since there's no simple way of pre-computing the size of the generated GIF image (short of running the compressor, which is a mildly expensive operation), I simply give it the size of the uncompressed bitmap buffer (in the io_open()).
Now that I've given you some background into why the code was designed the way it was, let's look at the resource manager portion of the code.
static int
io_open (resmgr_context_t *ctp, io_open_t *msg,
RESMGR_HANDLE_T *handle, void *extra)
{
IOFUNC_OCB_T *ocb;
int sts;
sts = iofunc_open (ctp, msg, &handle -> base, NULL, NULL);
if (sts != EOK) {
return (sts);
}
ocb = calloc (1, sizeof (*ocb));
if (ocb == NULL) {
return (ENOMEM);
}
// give them the unencoded size
handle -> base.nbytes = optx * opty;
sts = iofunc_ocb_attach (ctp, msg, &ocb -> base,
&handle -> base, NULL);
return (sts);
}
The only thing that's unique in this io_open() handler is that we allocate the OCB ourselves (we do this because we need a non standard size), and then jam the nbytes member with the raw uncompressed size, as discussed above.
In an earlier version of the code, instead of using the raw uncompressed size, I decided to call the 7-segment render function and to GIF-encode the output. I thought this was a good idea, reasoning that every time the client calls open() on the resource, I should increment the number. This way, too, I could give a more “realistic” size for the file (turns out that the compressed file is on the order of 5% of the size of the raw image). Unfortunately, that didn't work out because a lot of things end up causing the io_open() handler to run — things like ls would stat() the file, resulting in an inaccurate count. Some utilities prefer to stat() the file first, and then open it and read the data, causing the numbers to jump unexpectedly. I removed the code that generates the compressed stream from io_open() and instead moved it down to the io_read().
static int
io_read (resmgr_context_t *ctp, io_read_t *msg, RESMGR_OCB_T *ocb)
{
int nbytes;
int nleft;
int sts;
char string [MAX_DIGITS + 1];
// 1) we don't do any xtypes here...
if ((msg -> i.xtype & _IO_XTYPE_MASK) != _IO_XTYPE_NONE) {
return (ENOSYS);
}
// standard helper
sts = iofunc_read_verify (ctp, msg, &ocb -> base, NULL);
if (sts != EOK) {
return (sts);
}
// 2) generate and compress an image
if (!ocb -> output) {
unsigned char *input; // limited scope
input = calloc (optx, opty);
if (input == NULL) {
return (ENOMEM);
}
ocb -> output = calloc (optx, opty);
if (ocb -> output == NULL) {
free (input);
return (ENOMEM);
}
sprintf (string, "%0*d", optd, ocb -> base.attr -> count++);
render_7segment (string, input, optx, opty);
ocb -> size = encode_image (input, optx, opty, ocb -> output);
free (input);
}
// 3) figure out how many bytes are left
nleft = ocb -> size - ocb -> base.offset;
// 4) and how many we can return to the client
nbytes = min (nleft, msg -> i.nbytes);
if (nbytes) {
// 5) return it to the client
MsgReply (ctp -> rcvid, nbytes,
ocb -> output + ocb -> base.offset, nbytes);
// 6) update flags and offset
ocb -> base.attr -> base.flags |=
IOFUNC_ATTR_ATIME | IOFUNC_ATTR_DIRTY_TIME;
ocb -> base.offset += nbytes;
} else {
// 7) nothing to return, indicate End Of File
MsgReply (ctp -> rcvid, EOK, NULL, 0);
}
// 8) already done the reply ourselves
return (_RESMGR_NOREPLY);
}
Let's look at this code step-by-step:
|
Notice that we used the OCB's size member rather than the attributes structure's nbytes member. This is because the image that we generated has a different size (shorter) than the size stored in the attributes structure's nbytes member. Since we want to return the correct number of bytes to the client, we use the smaller size number. |
static int
io_close_ocb (resmgr_context_t *ctp, void *reserved,
RESMGR_OCB_T *ocb)
{
if (ocb -> output) {
free (ocb -> output);
ocb -> output = NULL;
}
return (iofunc_close_ocb_default (ctp, reserved,
&ocb -> base));
}
The io_close_ocb() function doesn't do anything special, apart from releasing the memory that may have been allocated in io_read(). The check to see if anything is present in the output member of the extended OCB structure is necessary because it's entirely possible that io_read() was never called and that member never had anything allocated to it (as would be the case with a simple stat() call — stat() doesn't cause read() to be called, so our io_read() would never get called).
I won't go into great detail on the render_7segment() function, except to describe in broad terms how it works.
Here's the prototype for render_7segment()
void
render_7segment (char *digits,
unsigned char *r,
int xsize,
int ysize);
The parameters are:
As an exercise for the reader, you can extend the character set accepted by the render_7segment() function. You'll want to pay particular attention to the seg7 array, because it contains the individual segment encodings for each character.
Finally, the encode_image() function is used to encode the raw bitmap array into a GIF compressed stream. This code was originally found in an antique version of FRACTINT (a Fractal graphics generator; see http://fractint.org/) that I had on my system from the BIX (Byte Information Exchange) days. I've simplified the code to deal only with a limited range of colors and a fixed input format. You'll need to provide your own version.
I won't go into great detail on the encode_image() function, but here's the prototype:
int
encode_image (unsigned char *raster,
int x,
int y,
unsigned char *output);
The parameters are:
Since we don't know a priori how big the compressed output buffer will be, I allocate one that's the same size as the input buffer. This is safe, because the nature of the 7-segment rendering engine is that there will be many “runs” (adjacent pixels with the same color), which are compressible. Also, the bitmap used is really only one bit (on or off), and the compressed output buffer makes full use of all 8 bits for the compressed streams. (If you modify this, beware that in certain cases, especially with “random” data, the compressed output size can be bigger than the input size.)
As another exercise, you can modify the webcounter resource manager to generate a JPEG or PNG file instead of, or in addition to, the GIF files that it currently generates.
The return value from the encode_image() function is the number of bytes placed into the compressed data buffer, and is used in io_read() to set the size of the resource.
Now that we understand the basic functionality of the web counter, it's time to move on to phase 2 of the project.
In this second phase, we're going to add (in order of increasing complexity):
Why these particular features, and not others? They're incremental, and they are more or less independent of each other, which means we can examine them one at a time, and understand what kind of impact they have on the code base. And, most of them are useful. :-)
The biggest modification is the ability to write() to the resource. What I mean by that is that we can set the counter's value by writing a value to it:
# echo 1234 >/dev/webcounter.gif
This will reset the counter value to 1234.
This modification will illustrate some aspects of accumulating data from a client's write() function, and then seeing how this data needs to be processed in order to interact correctly with the resource manager. We'll also look at extending this functionality later.
All of the modifications take place within main.c (with the exception of the font-selection modification, which also adds two new files, 8x8.c and 8x8.h).
Soon after finishing the phase 1 web counter, I realized that it really needed to be able to store the current count somewhere, so that I could just restart the web counter and have it magically continue from where it left off, rather than back at zero.
The first change to accomplish this is to handle the -S option, which lets you specify the name of the file that stores the current web counter value. If you don't specify a -S then nothing different happens — the new version behaves just the same as the old version. Code-wise, this change is trivial — just add “S:” to the getopt() string list in the command line option processor (optproc() in main.c), and put in a handler for that option. The handler saves the value into the global variable optS.
At the end of option processing, if we have a -S option, we read the value from it (by calling read_file()), but only if we haven't specified a -s. The logic here is that if you want to reset the web counter to a particular value, you'd want the -s to override the count from the -S option. (Of course, you could always edit the persistent data file with a text editor once the resource manager has been shut down.)
Once the web counter has started, we're done reading from the persistent count file. All we need to do is update the file whenever we update the counter. This too is a trivial change. After we increment the counter's value in io_read(), we call write_file() to store the value to the persistent file (only if optS is defined; otherwise, there's no file, so no need to save the value).
As it turns out, font selection is almost as trivial to implement as the persistent count file, above.
We had to add a -r option (for “render”), and a little bit of logic to determine which font was being specified:
case 'r':
if (!strcmp (optarg, "8x8")) {
optr = render_8x8;
} else if (!strcmp (optarg, "7seg")) {
optr = render_7segment;
} else {
// error message
exit (EXIT_FAILURE);
}
break;
The specified font is selected by storing a function pointer to the font-rendering function in the optr variable. Once that's done, it's a simple matter of storing the function pointer into a new field (called render) within the OCB:
typedef struct my_ocb_s
{
iofunc_ocb_t base;
unsigned char *output;
int size;
void (*render) (char *string,
unsigned char *bitmap,
int x, int y);
} my_ocb_t;
Then, in io_read(), we replaced the hard-coded call to render_7segment():
render_7segment (string, input, optx, opty);
with a call through the OCB's new pointer:
(*ocb -> render) (string, input, optx, opty);
Fairly painless. Of course, we needed to create a new font and font-rendering module, which probably took more time to do than the actual modifications. See the source in 8x8.c for the details of the new font.
The next modification is to make the resource manager return an ASCII string instead of a GIF-encoded image. You could almost argue that this should have been “Phase 0,” but that's not the way that the development path ended up going.
It would be simple to create a rendering module that copied the ASCII string sent to the “raw bitmap” array, and skip the GIF encoding. The code changes would be minimal, but there would be a lot of wasted space. The raw bitmap array is at least hundreds of bytes, and varies in size according to the X and Y sizes given on the command line. The ASCII string is at most 11 bytes (we impose an arbitrary limit of 10 digits maximum, and you need one more byte for the NUL terminator for the string). Additionally, having the resource manager register a name in the pathname space that ends in .gif, and then having text come out of the GIF-encoded “file” is a little odd.
Therefore, the approach taken was to create a second pathname that strips the extension and adds a different extension of “.txt” for the text version. We now have two attributes structures: one for the original GIF-encoded version and another for the text version.
|
This is a fairly common extension to resource managers in the field. Someone decides they need data to come out of the resource manager in a different format, so instead of overloading the meaning of the registered pathname, they add a second one. |
The first change is to create the two attributes structures in execute_resmgr(). So, instead of:
static void
execute_resmgr (void)
{
resmgr_attr_t resmgr_attr;
resmgr_connect_funcs_t connect_func;
resmgr_io_funcs_t io_func;
my_attr_t attr;
dispatch_t *dpp;
resmgr_context_t *ctp;
…
we now have:
// one for GIF, one for text
static my_attr_t attr_gif;
static my_attr_t attr_txt;
static void
execute_resmgr (void)
{
resmgr_attr_t resmgr_attr;
resmgr_connect_funcs_t connect_func;
resmgr_io_funcs_t io_func;
dispatch_t *dpp;
resmgr_context_t *ctp;
…
Notice how we moved the two attributes structures out of the execute_resmgr() function and into the global space. You'll see why we did this shortly. Ordinarily, I'd be wary of moving something into global space. In this case, it's purely a scope issue — the attributes structure is a per-device structure, so it doesn't really matter where we store it.
Next, we need to register the two pathnames instead of just the one. There are some code modifications that we aren't going to discuss in this book, such as initializing both attributes structures instead of just the one, and so on. Instead of:
// establish a name in the pathname space
if (resmgr_attach (dpp, &resmgr_attr, optn, _FTYPE_ANY, 0,
&connect_func, &io_func, &attr) == -1) {
perror ("Unable to resmgr_attach()\n");
exit (EXIT_FAILURE);
}
we now have:
// establish a name in the pathname space for the .GIF file:
if (resmgr_attach (dpp, &resmgr_attr, optn, _FTYPE_ANY, 0,
&connect_func, &io_func, &attr_gif) == -1) {
perror ("Unable to resmgr_attach() for GIF device\n");
exit (EXIT_FAILURE);
}
// establish a name in the pathname space for the text file:
convert_gif_to_txt_filename (optn, txtname);
if (resmgr_attach (dpp, &resmgr_attr, txtname, _FTYPE_ANY, 0,
&connect_func, &io_func, &attr_txt) == -1) {
perror ("Unable to resmgr_attach() for text device\n");
exit (EXIT_FAILURE);
}
The convert_gif_to_txt_filename() function does the magic of stripping out the extension and replacing it with “.txt.” It also handles other extensions by adding “.txt” to the filename.
At this point, we have registered two pathnames in the pathname space. If you didn't specify a name via -n, then the default registered names would be:
/dev/webcounter.gif /dev/webcounter.txt
Notice how we don't change the count based on reading the text resource. This was a conscious decision on my part — I wanted to be able to read the “current” value from the command line without affecting the count:
cat /dev/webcounter.txt
The rationale is that we didn't actually read the web page; it was an administrative read of the counter, so the count should not be incremented. There's a slight hack here, in that I reach into the GIF's attributes structure to grab the count. This is acceptable, because the binding between the two resources (the GIF-encoded resource and the text resource) is done at a high level.
The final change we'll make to our resource manager is to give it the ability to handle the client's write() requests. Initially, the change will be very simple — the client can write a number up to MAX_DIGITS (currently 10) digits in length, and when the client closes the file descriptor, that number will be jammed into the current count value. This lets you do the following from the command line:
echo 1433 >/dev/webcounter.gif
or
echo 1433 >/dev/webcounter.txt
We're not going to make any distinction between the GIF-encoded filename and the text filename; writing to either will reset the counter to the specified value, 1433 in this case (yes, it's a little odd to write a plain ASCII string to a .gif file).
If we're going to be handling the client's write() function, we need to have an io_write() handler. This is added in execute_resmgr() to the table of I/O functions, right after the other functions that we've already added:
// override functions in "connect_func" and // "io_func" as required here connect_func.open = io_open; io_func.read = io_read; io_func.close_ocb = io_close_ocb; io_func.write = io_write; // our new io_write handler
What are the characteristics of the io_write() handler?
First of all, it must accumulate characters from the client. As with the io_read() handler, the client can “dribble” in digits, one character at a time, or the client can write() the entire digit stream in one write() function call. We have to be able to handle all of the cases. Just like we did with the io_read() handler, we'll make use of the OCB's offset member to keep track of where we are in terms of reading data from the client. The offset member is set to zero (by the calloc() in io_open()) when the resource is opened, so it's already initialized.
We need to ensure that the client doesn't overflow our buffer, so we'll be comparing the offset member against the size of the buffer as well.
We need to determine when the client is done sending us data. This is done in the io_close_ocb() function, and not in the io_write() function.
Let's look at the io_write() function first, and then we'll discuss the code:
static int
io_write (resmgr_context_t *ctp, io_write_t *msg, RESMGR_OCB_T *ocb)
{
int nroom;
int nbytes;
// 1) we don't do any xtypes here...
if ((msg -> i.xtype & _IO_XTYPE_MASK) != _IO_XTYPE_NONE) {
return (ENOSYS);
}
// standard helper function
if ((sts = iofunc_write_verify (ctp, msg, &ocb -> base, NULL)) != EOK) {
return (sts);
}
// 2) figure out how many bytes we can accept in total
nroom = sizeof (ocb -> wbuf) - 1 - ocb -> base.offset;
// 3) and how many we can accept from the client
nbytes = min (nroom, msg -> i.nbytes);
if (nbytes) {
// 4) grab the bytes from the client
memcpy (ocb -> wbuf + ocb -> base.offset, &msg -> i + 1, nbytes);
// 5) update flags and offset
ocb -> base.attr -> base.flags |=
IOFUNC_ATTR_MTIME | IOFUNC_ATTR_DIRTY_TIME;
ocb -> base.offset += nbytes;
} else {
// 6) we're full, tell them
if (!nroom) {
return (ENOSPC);
}
}
// 7) set the number of returning bytes
_IO_SET_WRITE_NBYTES (ctp, nbytes);
return (EOK);
}
The io_write() function performs the following steps:
|
In step 4, we assume that we have all of the data! Remember that the resource manager framework doesn't necessarily read in all of the bytes from the client — it reads in only as many bytes as you've specified in your resmgr_attr.msg_max_size parameter to the resmgr_attach() function (and in the network case it may read in less than that). However, we are dealing with tiny amounts of data — ten or so bytes at the most, so we are safe in simply assuming that the data is present. For details on how this is done “correctly,” take a look at the RAM-disk Filesystem chapter. |
Finally, here are the modifications required for the io_close_ocb() function:
static int
io_close_ocb (resmgr_context_t *ctp, void *reserved, RESMGR_OCB_T *ocb)
{
int tmp;
if (ocb -> output) {
free (ocb -> output);
ocb -> output = NULL;
}
// if we were writing, parse the input
// buffer and possibly adjust the count
if (ocb -> base.ioflag & _IO_FLAG_WR) {
// ensure NUL terminated and correct size
ocb -> wbuf [optd + 1] = 0;
if (isdigit (*ocb -> wbuf)) {
attr_gif.count = attr_txt.count = tmp = atoi (ocb -> wbuf);
if (optS) {
write_file (optS, tmp);
}
}
}
return (iofunc_close_ocb_default (ctp, reserved, &ocb -> base));
}
All that's different in the io_close_ocb() function is that we look at the OCB's ioflag to determine if we were writing or not. Recall that the ioflag is the “open mode” plus one — by comparing against the constant _IO_FLAG_WR we can tell if the “write” bit is set. If the write bit is set, we were writing, therefore we process the buffer that we had been accumulating in the io_write(). First of all, we NULL-terminate the buffer at the position corresponding to the number of digits specified on the command line (the -d option, which sets optd). This ensures that the atoi() call doesn't run off the end of the string and into Deep Outer Space (DOS) — this is redundant because we calloc() the entire OCB, so there is a NULL there anyway. Finally, we write the persistent counter file if optS is non-NULL.
We check to see if the first character is indeed a digit, and jam the converted value into both attribute structures' count members. (The atoi() function stops at the first non digit.)
This is where you could add additional command parsing if you wanted to. For example, you might allow hexadecimal digits, or you might wish to change the background/foreground colors, etc., via simple strings that you could echo from the command line:
echo "bgcolor=#FFFF00" >/dev/webcounter.gif
This is left as an exercise for the reader.
In the last phase of our project, we're going to change from managing one file at a time to managing multiple counters.
What this means is that we'll take over a directory instead of a file or two, and we'll be able to present multiple counters. This is useful in the real world if, for example, you want to be able to maintain separate counters for several web pages.
Before we tackle that, though, it's worthwhile to note that you could achieve a similar effect by simply performing more resmgr_attach() calls; one pair of resources (the GIF-encoded and the text file) per web counter. The practical downside of doing this is that if you are going to be attaching a lot of pathnames, Neutrino's process manager will need to search through a linear list in order to find the one that the client has opened. Once that search is completed and the resource is opened, however, the code path is identical. All we're doing by creating a directory instead of a pathname is moving the pathname-matching code into our resource manager instead of the process manager.
The main differences from the previous version will be:
There are a number of “tricks” that we can play when we manage our own pathname space. For example, instead of having a plain filename for the web resource, we can have a built-in command in the resource filename, like this:
/dev/webcounters/counter-00.gif/fg=#ffff00,bg=#00ffa0
(I would have really liked to put a “?” character instead of the last “/” character, but web-browsers strip off anything after (and including) the “?” character; plus it would be cumbersome to use within the shell). Here, we're accessing the /dev/webcounters/counter-00.gif resource, and “passing” it the arguments for the foreground and background colors.
The process manager doesn't care about the pathname after our registered mount point. In this example, our mount point is just /dev/webcounters — anything after that point is passed on to our io_open() as a text string. So in this case, our io_open() would receive the string:
counter-00.gif/fg=#ffffff0,bg=#00ffa0
How we choose to interpret that string is entirely up to us. For simplicity, we won't do any fancy processing in our resource manager, but I wanted to point out what could be done if you wanted to.
Our resource manager will accept a fixed-format string, as suggested above. The format is the string “counter-” followed by two decimal digits, followed by the string “.gif” and nothing further. This lets our io_open() code parse the string quite simply, and yet demonstrates what you can do.
|
This is one of the reasons that our pathname parsing will be faster than the generic linear search inside of the process manager. Since our filenames are of a fixed form, we don't actually “search” for anything, we simply convert the ASCII number to an integer and use it directly as an index. |
The default number of counters is set to 100, but the command-line option -N can be used to set a different number.
We're also going to reorganize the storage file format of the persistent counter a little bit just to make things simpler. Rather than have 100 files that each contain one line with the count, instead we're going to have one file that contains 100 32-bit binary integers (i.e. a 400-byte file).
There are a number of architectural changes required to go from a single pair of file-type resources to a directory structure that manages a multitude of pairs of file-type resources.
The first thing I did was add a few new global variables, and modify others:
You'll notice that the attributes structures and the OCB remain the same as before; no changes are required there.
We need to change the execute_resmgr() function a little. We're no longer registering a pair of file-type resources, but rather just a single directory.
Therefore, we need to allocate and initialize the arrays attr_gif and attr_txt so that they contain the right information for the GIF-encoded and text files:
// initialize the individual attributes structures
for (i = 0; i < optN; i++) {
iofunc_attr_init (&attr_gif [i].base, S_IFREG | 0666, 0, 0);
iofunc_attr_init (&attr_txt [i].base, S_IFREG | 0666, 0, 0);
// even inodes are TXT files
attr_txt [i].base.inode = (i + 1) * 2;
// odd inodes are GIF files
attr_gif [i].base.inode = (i + 1) * 2 + 1;
}
It's important to realize that the attributes structure's inode (or “file serial number”) member plays a key role. First of all, the inode cannot be zero. To Neutrino, this indicates that the file is no longer in use. Therefore, our inodes begin at 2. I've made it so that even-numbered inodes are used with the text files, and odd-numbered inodes are used with the GIF-encoded files. There's nothing saying how you use your inodes; it's completely up to you how you interpret them — so long as all inodes in a particular filesystem are unique.
We're going to use the inode to index into the attr_gif and attr_txt attributes structures. We're also going to make use of the even/odd characteristic when we handle the client's read() function.
Next, we initialize the attributes structure for the directory itself:
iofunc_attr_init (&attr.base, S_IFDIR | 0777, 0, 0); // our directory has an inode of one. attr.base.inode = 1;
Notice the S_IFDIR | 0777 — this sets the mode member of the attributes structure to indicate that this is a directory (the S_IFDIR part) and that the permissions are 0777 — readable, writable, and seekable by all.
Finally, we register the pathname with the process manager:
if (resmgr_attach (dpp, &resmgr_attr, optn, _FTYPE_ANY,
_RESMGR_FLAG_DIR, &connect_func, &io_func, &attr) == -1) {
perror ("Unable to resmgr_attach()\n");
exit (EXIT_FAILURE);
}
Notice that this time there is only one resmgr_attach() call — we're registering only one pathname, the directory. All of the files underneath the directory are managed by our resource manager, so they don't need to be registered with the process manager. Also notice that we use the flag _RESMGR_FLAG_DIR. This tells the process manager that it should forward any requests at and below the registered mount point to our resource manager.
The change to the option processing is almost trivial. We added “N:” to the list of options processed by getopt() and we added a case statement for the -N option. The only funny thing we do is calculate the number of digits that the number of counters will require. This is done by calling sprintf() to generate a string with the maximum value, and by using the return value as the count of the number of digits. We need to know the size because we'll be using it to match the filenames that come in on the io_open(), and to generate the directory entries.
Finally, we initialize the attributes structure in the option processor (instead of execute_resmgr() as in previous versions) because we need the attributes structures to exist before we call read_file() to read the counter values from the persistent file.
This is where things get interesting. Our io_read() function gets called to handle three things:
The first two operate on a file, and the last operates on a directory. So that's the first decision point in our new io_read() handler:
static int
io_read (resmgr_context_t *ctp, io_read_t *msg, RESMGR_OCB_T *ocb)
{
int sts;
// use the helper function to decide if valid
if ((sts = iofunc_read_verify (ctp, msg, &ocb -> base, NULL)) != EOK) {
return (sts);
}
// decide if we should perform the "file" or "dir" read
if (S_ISDIR (ocb -> base.attr -> base.mode)) {
return (io_read_dir (ctp, msg, ocb));
} else if (S_ISREG (ocb -> base.attr -> base.mode)) {
return (io_read_file (ctp, msg, ocb));
} else {
return (EBADF);
}
}
By looking at the attributes structure's mode field, we can tell if the request is for a file or a directory. After all, we set this bit ourselves when we initialized the attributes structures (the S_IFDIR and S_IFREG values).
If we are handling a file, then we proceed to io_read_file(), which has changed slightly from the previous version:
…
// 1) odd inodes are GIF files, even inodes are text files
if (ocb -> base.attr -> base.inode & 1) {
if (!ocb -> output) {
…
// 2) allocate the input and output structures as before
…
sprintf (string, "%0*d", optd, ocb -> base.attr -> count++);
(*ocb -> render) (string, input, optx, opty);
ocb -> size = ocb -> base.attr -> base.nbytes = encode_image (
input, optx, opty, ocb -> output);
// 3) note the changes to write_file()
if (optS) {
write_file (optS, ocb -> base.attr -> base.inode / 2 - 1,
ocb -> base.attr -> count);
}
}
} else { // 4) even, so must be the text attribute
int tmp; // limited scope
ocb -> base.attr -> count =
attr_gif [ocb -> base.attr -> base.inode / 2 - 1].count;
tmp = sprintf (string, "%0*d\n", optd, ocb -> base.attr -> count);
if (ocb -> output) {
free (ocb -> output);
}
ocb -> output = strdup (string);
ocb -> size = tmp;
}
Notice a few things:
What might appear to be “clever” use of inodes is in fact standard programming practice. When you think about it, a disk-based filesystem makes use of the inodes in a similar manner; it uses them to find the disk blocks on the media.
Our resource manager needs to be able to handle an ls of the directory.
|
While this isn't an absolute requirement, it's a “nice-to-have.” It's acceptable to simply lie and return nothing for the client's readdir(), but most people consider this tacky and lazy programming. As you'll see below, it's not rocket science. |
I've presented the code for returning directory entries in the “Resource Managers” chapter of my previous book, Getting Started with QNX Neutrino. This code is a cut-and-paste from the atoz resource manager example, with some important changes.
#define ALIGN(x) (((x) + 3) & ~3)
This is an alignment macro to help align things on a 32-bit boundary within the struct dirent that we are returning.
static int
io_read_dir (resmgr_context_t *ctp, io_read_t *msg,
RESMGR_OCB_T *ocb)
{
int nbytes;
int nleft;
struct dirent *dp;
char *reply_msg;
char fname [PATH_MAX];
// 1) allocate a buffer for the reply
reply_msg = calloc (1, msg -> i.nbytes);
if (reply_msg == NULL) {
return (ENOMEM);
}
// 2) assign output buffer
dp = (struct dirent *) reply_msg;
// 3) we have "nleft" bytes left
nleft = msg -> i.nbytes;
while (ocb -> base.offset < optN * 2) {
// 4) create the filename
if (ocb -> base.offset & 1) {
sprintf (fname, "counter-%0*d.gif",
optNsize, (int) (ocb -> base.offset / 2));
} else {
sprintf (fname, "counter-%0*d.txt",
optNsize, (int) (ocb -> base.offset / 2));
}
// 5) see how big the result is
nbytes = dirent_size (fname);
// 6) do we have room for it?
if (nleft - nbytes >= 0) {
// 7) fill the dirent, advance the dirent pointer
dp = dirent_fill (dp, ocb -> base.offset + 2,
ocb -> base.offset, fname);
// 8) move the OCB offset
ocb -> base.offset++;
// 9) account for the bytes we just used up
nleft -= nbytes;
} else {
// 10) don't have any more room, stop
break;
}
}
// 11) return info back to the client
MsgReply (ctp -> rcvid, (char *) dp - reply_msg,
reply_msg, (char *) dp - reply_msg);
// 12) release our buffer
free (reply_msg);
// 13) tell resmgr library we already did the reply
return (_RESMGR_NOREPLY);
}
Now I'll walk you through the code:
|
In step 4, we need to make note of the relationship between inode values and the offset member of the OCB. The meaning of the offset member is entirely up to us — all that Neutrino demands is that it be consistent between invocations of the directory-reading function. In our case, I've decided that the offset member is going to be directly related to the array index (times 2) of the two arrays of attributes structures. The array index is directly related to the actual counter number (i.e. an array index of 7 corresponds to counter number 7). |
static int
dirent_size (char *fname)
{
return (ALIGN (sizeof (struct dirent) - 4 + strlen (fname)));
}
static struct dirent *
dirent_fill (struct dirent *dp, int inode, int offset, char *fname)
{
dp -> d_ino = inode;
dp -> d_offset = offset;
strcpy (dp -> d_name, fname);
dp -> d_namelen = strlen (dp -> d_name);
dp -> d_reclen = ALIGN (sizeof (struct dirent)
- 4 + dp -> d_namelen);
return ((struct dirent *) ((char *) dp + dp -> d_reclen));
}
These two utility functions calculate the size of the directory entry (dirent_size()) and then fill it (dirent_fill()).
Finally, the last thing to modify is the utilities that manage the persistent counter file, read_file() and write_file().
The changes here are very simple. Instead of maintaining one counter value in the file (and in ASCII text at that), we maintain all of the counter values in the file, in binary (4 bytes per counter, native-endian format).
This implies that read_file() needs to read the entire file and populate all of the counter values, while write_file() needs to write the value of the counter that has changed, and leave the others alone. This also, unfortunately, implies that we can no longer modify the file “by hand” using a regular text editor, but instead must use something like spatch — this is fine, because we still have the ability to write() a number to the resource manager's “files.”
I've used the buffered I/O library (fopen(), fread(), fwrite())) in the implementation, and I fopen() and fclose() the file for each and every update. It would certainly be more efficient to use the lower-level I/O library (open(), read(), write(), etc.), and consider leaving the file open, rather than opening and closing it each time. I stayed with buffered I/O due to, yes, I'll admit it, laziness. The original used fopen() and fprintf() to print the counter value in ASCII; it seemed easier to change the fprintf() to an fseek()/fwrite().
The ability to have each web counter be a different size (and that information stored in a persistent configuration file), or to have the size specified as a “trailer” in the pathname, is something that can be added fairly easily. Try it and see!
The following references apply to this chapter.
See the following functions in the Neutrino C library reference:
Getting Started with QNX Neutrino's Resource Managers chapter goes into exhaustive detail about handling resource managers.